|
libQtCassandra 0.3.2
|
|
libQtCassandra 0.3.2
|
-- libQtCassandra copyright and license
It looks like there was a need for a C++ library for the Cassandra system. Looking around the only one available was indeed in C++ and helping a bit by hiding some of the Thrift implementation, but in the end you still had to know how the Thrift structure had to be used to make it all work.
So, I decided to write my own version, especially, I was thinking that it should be possible to access the data with the following simple array like syntax:
cluster[context][table][row][column] = value; value = cluster[context][table][row][column];
In other words, you should be able to create a cluster object and then from that object access the contexts (keyspaces), the tables (column families), the rows and columns (actually, the values are saved in cells in this library, but the name used in the cell is the name of the column.)
Looking at the implementation of a system I will create soon after having done this library it very much feels like this is going to be the basis for many accesses to the Cassandra database.
The cluster is defined in a QCassandra object. At the time you call connect() you get a connection to the Cassandra server and you can start using the other functions.
Clusters are used to manage contexts and to access the Cassandra server.
Note that internally all accesses to the Cassandra system is done with one f_client pointer.
A cluster can have many contexts. It has the default System contexts that comes with the Cassandra environment. Others can be create()'d, and opened on later connections.
Contexts can be used to manage tables.
A table has a name and it includes one to many rows. The number of rows can be really large and not impact the database system much.
The readRows() function is used to read a range of rows as determined by the row predicate.
A table may have a list of column definitions. You generally do not need a column definition unless you want to force a certain type of data in a column. In that case a column definition is required (Assuming that the default type is not what you want for that column.)
We do not use this information internally. Only to forward to the Cassandra server (and also we read the current status from the Cassandra server.)
At a later time, we may check the type defined here and in the row (if not defined as a column type) and check the data supplied to verify that the data passed to the row is valid before sending it to the server. This is probably not necessary because if you have bad data your application won't work, no matter what.
A row is named using a key, which means the name can include any character including '\0' (it just cannot be empty.) Rows include cells.
Contrary to an SQL engine where the number of columns is generally relatively restrained, the number of cells in a row can be very large and accessing a specific cell remains fast (assuming the cell names remain reasonably small.)
For this reason, when you read a row, you do not have to read all the cells on that row. Instead, you may read just one cell (for example.)
A cell is named using a column key, which manes the name can include any character including '\0' (it just cannot be empty.) Cells also define a value.
Note that when you create an index, you may use a default value (including the Null value.) For example, if you have a Page table with a row numbered 3 and that row has a cell named Path with a value X. You may add this row like this (somewhat simplified for this example):
// add the value "X" to row "3" in table "Page" int64_t row_number = 3; QCassandraValue row_id; row_id = row_number; QCassandraValue value; value = "X"; context["Page"][row_id]["Path"] = value; // "simultaneously," create an index from value to row identifier QCassandraValue empty; context["Page_Path_Index"][value][row_id] = empty; // search rows in pages that have a path set to value context["Page_Path_Index"][value].readCells(predicate);
As you can see, the second write uses the empty value so you do not waste any space in the database.
The cells are set to a specific value using the QCassandraValue class. Beside their binary data, values have a timestamp that represents the time and date when they were created and a TTL (time to live) value in seconds. By default the timestamp is set to gettimeofday() and the TTL is set to 0 (which means permanent.)
The values are cached in memory by the libQtCassandra library. Not only that, multiple write of the same value to the same cell will generate a single write to the Cassandra database (i.e. the timestamp is ignored in this case, see the QCassandraCell class for more info.)
Values also include a consistency level. By default this is set to ONE which may not be what you want to have... (in many cases QUORUM is better.) The consistency level is defined here because it can then easily be propagated when using the array syntax.
QCassandraValue v; v.setDoubleValue(3.14159); v.setConsistencyLevel(QtCassandra::CONSISTENCY_LEVEL_EACH_QUORUM); v.setTimestamp(counter); v.setTtl(60 * 60 * 24); // live for 1 day ...
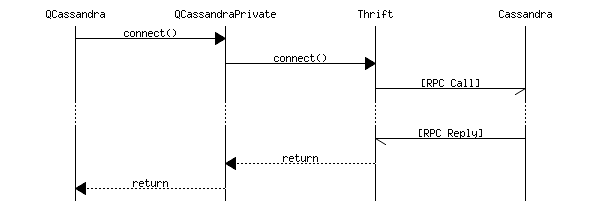
In general, the objects communicate between parent and child. However, some times the children need to access the QCassandraPrivate functions to send an order to the Cassandra server. This is done by implementing functions in the parents and calling functions in cascade.
The simplest message sent to the Cassandra server comes from the connect() which is the first time happen. It starts from the QCassandra object and looks something like this:
When you save a QCassandraValue in a QCassandraCell, then the cell calls the row, which calls the table, which calls the context which has access to the QCassandraPrivate:
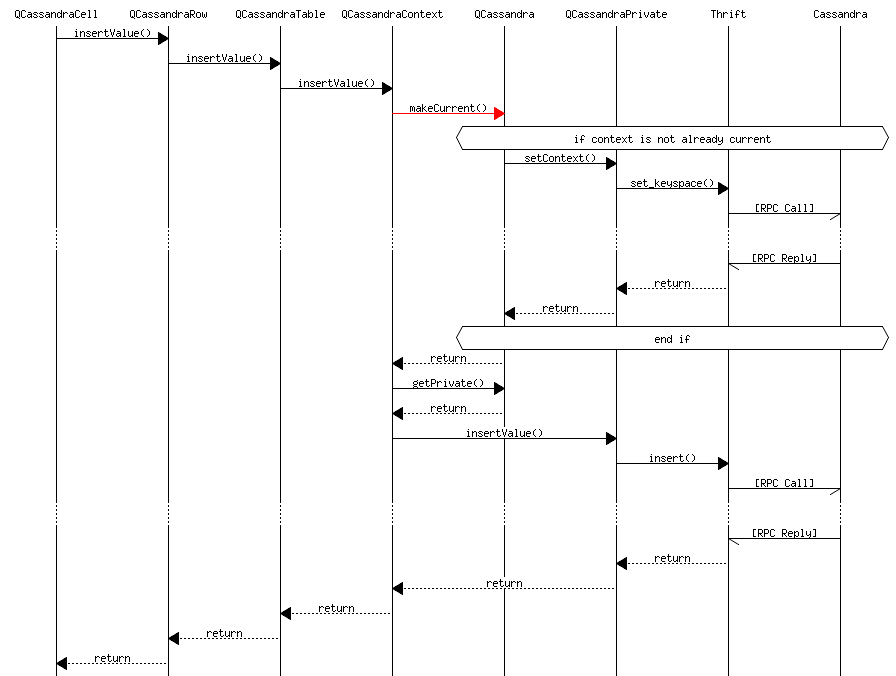
As you can see the context makes itself current as required. This ensures that the correct context is current when a Cassandra RPC event is sent. This is completely automatic so you do not need to know whether the context is current. Note that the function is optimized (i.e. the pointer of the current context is saved in the QCassandra object so if it doesn't change we avoid the set_keyspace() call.)
Messages from rows, tables, and contexts work the same way, only they do not include calls from the lower layers.
The drop() calls have one additional call which deletes the children that were just dropped. (i.e. if you drop a row, then its cells are also dropped.)
The libQtCassandra library is NOT multi-thread safe. This is for several reasons, the main one being that we are not currently looking into writing multi-threaded applications (on a server with a heavy load, you have many processes running in parallel and having multiple threads in each doesn't save you anything.)
If you plan to have multiple threads, I currently suggest you create one QCassandra object per thread. The results will be similar, although it will make use of more memory and more accesses to the Cassandra server (assuming each thread accesses the common data, in that case you probably want to manage your own cache of the data.)
First of all, calm down, you won't need to run X or some other graphical environment. We only use QtCore.
Qt has many objects ready made that work. It seems to make sense to use them. More specifically, it has a QString which supports UTF-8 out of the box. So instead of using iconv and std::string, Qt seems like a good choice to me.
The main objects we use are the QString, QByteArray, QMap, QVector, and QObject. The QByteArray is used to transport binary data. The QMap is used to sort out the list of contexts, tables, rows, cells, and column definitions.
Note that the QByteArray has a great advantage over having your own buffer: it knows how to share its data pointer between multiple instances. Only a write will require a copy of the data buffer.
Many of the classes in the libQtCassandra derive from the QObject class. This means they cannot be copied. Especially, the QCassandra object which includes the socket connection to the Cassandra server (on top of the contexts, tables, rows, cells, column definitions... and since they all have a parent/child scheme!)
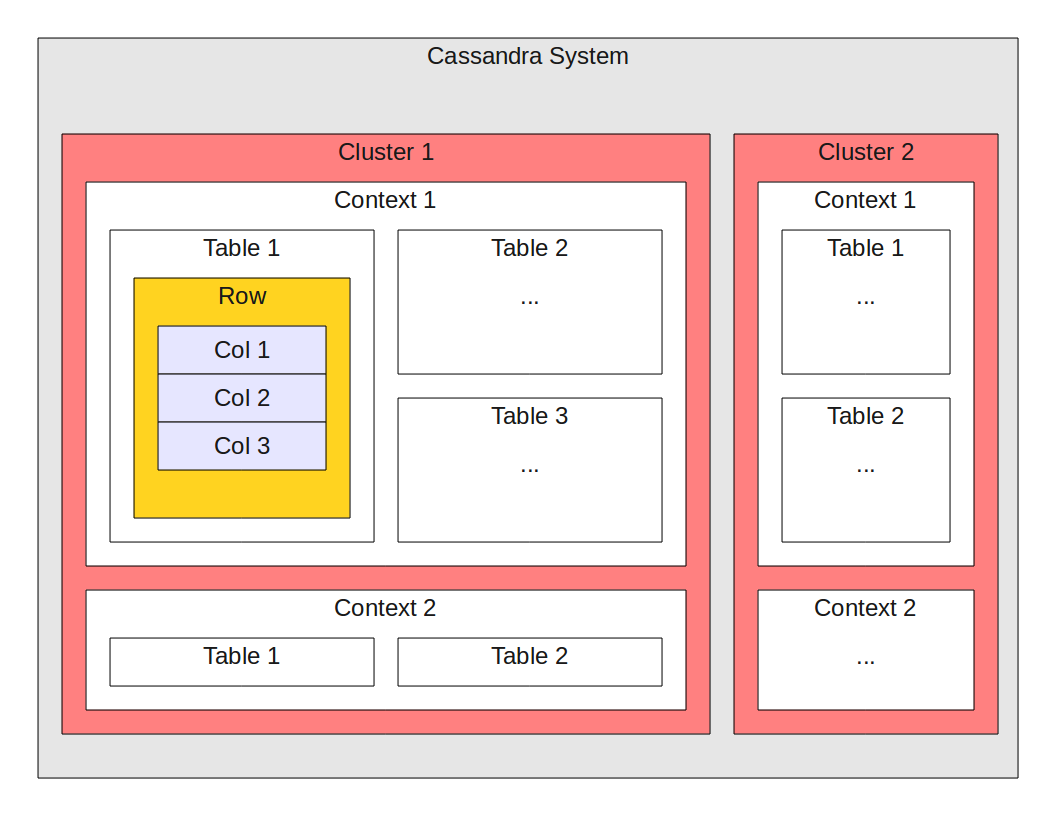
The Cassandra System comes with a terminology that can easily throw off people who are used to more conventional database systems (most of that terminology comes from the Big Table document by Google.)
This library attempts to hide some of the Cassandra terminology by offering objects that seem to be a little closer to what you'd otherwise expect in a database environment.
One Cassandra server instance runs against one cluster. We kept the term cluster as it is the usual term for a set of databases. Writing this in terms of C++ array syntax, the system looks like a multi-layer array as in (you can use this syntax with libQtCassandra, btw):
cluster[context][table][row][column] = value; value = cluster[context][table][row][column];
Note that in Cassandra terms, it would look like this instead:
cluster[keyspace][column_family][key][column] = value; value = cluster[keyspace][column_family][key][column];
One cluster is composed of multiple contexts, what Cassandra calls a keyspace. One context corresponds to one database. A context can be setup to replicate or not and it manages memory caches (it includes many replication and cache parameters.) We call these the context because once a cluster connection is up, you can only have one active context at a time. (If you worked with OpenGL, then this is very similar to the glMakeCurrent() function call.)
Although the libQtCassandra library 100% hides the current context calls since it knows when a context or another needs to be curent, switching between contexts can be costly. Instead you may want to look into using two QCassandra objects each with a different context.
Different contexts are useful in case you want to use one context for statistic data or other data that are not required to be read as quickly as your main data and possibly needs much less replication (i.e. ONE for writes and ALL for reads on a statistic table would work greatly.)
One context is composed of tables, what Cassandra calls a column family. By default, all the tables are expected to get replicated as defined in this context. However, some data may be marked as temporary with a time to live (TTL). Data with a very small TTL is likely to only live in the memory cache and never make it to the disk.
Note that the libQtCassandra library let you create table objects that do not exist in the Cassandra system. These are memory only tables (when you quite they're gone!) These can be used to manage run-time globals via the libQtCassandra system. Obviously, it would most certainly be more effective (faster) to just use globals. However, it can be useful to call a function that usually accesses a Cassandra table, but in that case you dynamically generate said data.
A table is identified by a name. At this time, we only offer QString for table names. Table names must be letters, digits and the underscore. This limitation comes from the fact that it is used to represent a filename. Similarly, it may be limited in length (OS dependent I guess, the Cassandra system does not say from what I've seen. Anyway it should be easy to keep the table names small.)
Tables are composed of rows. Here the scheme somewhat breaks from the usual SQL database as rows are independent from each others. This is because one row may have 10 "columns," and the other may have just 1. Each row is identified by what Cassandra calls a key. The key can either be a string or a binary identifier (i.e. an int64_t for example.)
The name of a row can be typed. In most cases, the default binary type is enough (assuming you save integers in big endians, which is what the libQtCassandra does.) This is important when you want to use a Row Predicate.
Rows are composed of cells. Cassandra calls them columns, but in practice, the name/value pair is just a Cell. Although some tables may define column types and those cells (with the same name) will then be typed and part of that column.
A column is a name and a value pair. It is possible to change the characteristics of a column on how it gets duplicated, cached, and how the column gets compared with a Column Predicate.
The name of a column can be a QString or binary data. It is often a QString as it looks like the name of a variable (var=<value>).
The row and column names are both limited to 64Kb. The value of a column is currently limited to 2Gb, however, you'll need a HUGE amount of memory (~6Gb+) to be able to handle such large values and not only that, you need to do it serially (i.e. one process at a time can send that much data or the memory will quickly exhaust and the processes will fail.) It is strongly advised that you limit your values to Mb instead.
By default, the QCassandra object checks the size with a much small limit (64Mb) to prevent problems. At a later time, we may offer a blob handling that will save large files by breaking them up in small parts saved in the Cassandra database.
In general, the libQtCassandra documentation will tell you how things work in the function you're trying to use. This means you should not really need to know all the details about the Cassandra system up front to start using it in C++ with this library.
For example, the QCassandraTable::dropRow() function works. The row doesn't disappear immediately from the database, but all the cells are. The QCassandraTable::readRows() function will correctly skip the row as long as you include at least one column in your predicate. All of these details are found in the corresponding function documentation.
Actual Cassandra's FAQ: http://wiki.apache.org/cassandra/FAQ
Copyright (c) 2011 Made to Order Software Corp.
http://snapwebsites.org/
contact@m2osw.com
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
This document is part of the libQtCassandra Project.
Copyright by Made to Order Software Corp.

